I’ve already written a post on using a piecewise-linear scaling to bring BM25 and my semantic score (from cosine similarity with our embeddings) into the same numerical space. After performing this scaling, I found some important results weren’t scoring as well as they should.
In particular, any search query with a common term (e.g. “the” or “history”) would have lower BM25 scores compared to the semantic scores. The reason for this was I was dividing BM25 by the number of terms in the query. I included that normalization, because otherwise adding more terms to the query would simply add to the overall BM25 score. For example,
Dividing by the number of terms averages the BM25 scores of each query term. But common terms have a low IDF and contribute little to the overall BM25. Consequently, they bring down the average BM25 score.
Gemini suggested a few ways around this:
Convex Combination with Reciprocal Rank Fusion
Instead of trying to normalize scores, you take the rank of the results within each individual score and use that to determine a new score:
where k is some constant like 60 that dampens high scores of only one type. For example, we’d retrieve and order documents by their BM25 score, then assign those results ranks . And then we’d use in place of the original BM25 score.
This is a really simple technique to implement and it’s apparently used by Asure AI search and Elasticsearch, but it’s not a great scoring function. It loses a ton of information. For instance, if my first ranked BM25 score was huge and my second was small, that’s an indication that my first result is much better than my second. And that should be taken into account when combing BM25 scores with the the semantic score. Similarly, we lose all sense of the absolute size of the scores. Maybe my BM25 scores are all small, and really I should weigh the semantic scores more.
Query-Time Stopword Filtering
The next suggestion is to identify common words and drop them from the query unless it’s part of a quoted phrase. This is a pretty blunt tool and I’m not sure how to implement it without causing all sorts of quality problems. I don’t want to drop common words from my index entirely or I’ll have blind spots. Really what I want is query processing step which will tell me what words are critical to the query and which are not.
For example, if I’m looking for the Alfred Hitchcock movie “The Birds”, I’m going to give pretty poor results if I drop “the”.
Likewise, there’s going to be times when all the words in the query are common and we have to do the hard word of finding documents where they’re important. For example “recent history”.
I plan to come back to stop-word filtering to see if it can be used appropriately.
IDF-Weighted Average
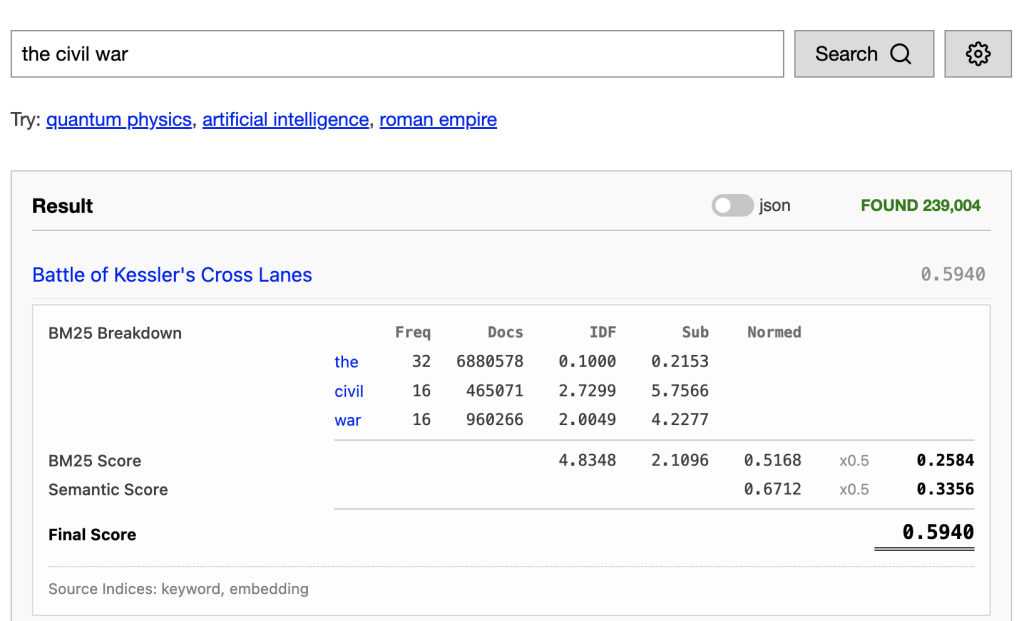
This is the recommendation I settled on. Rather than treat every word in the query with equal weight, we use the inverse-document-frequency to determine the word’s weight. So, in our “the civil war” example above, rather than treating this as 3 words, we treat it as a query with weight:
After dividing the BM25 by this weight, I had to recalculate my piecewise-linear scaling to align BM25 and the semantic scores.
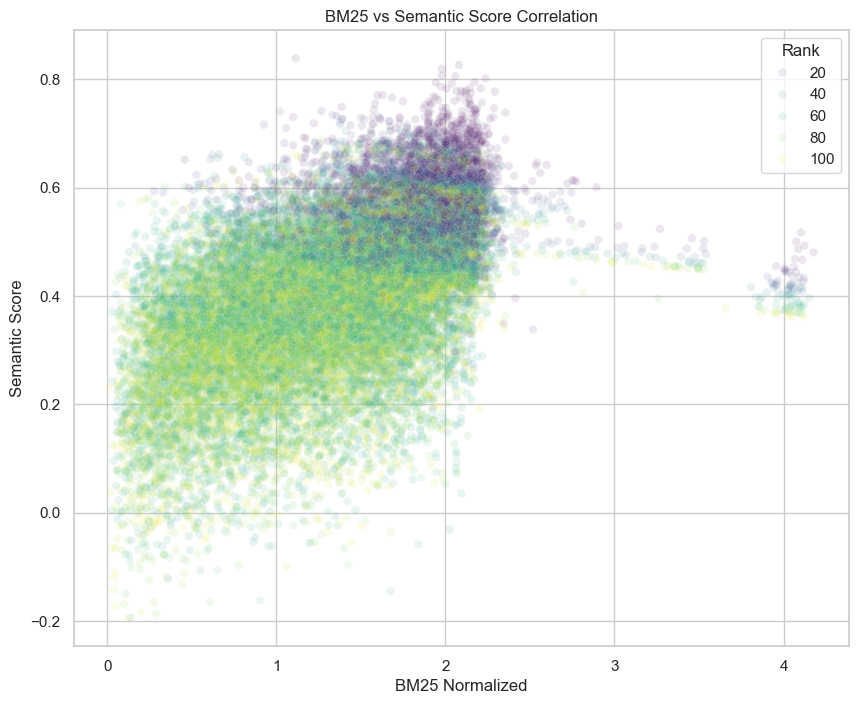
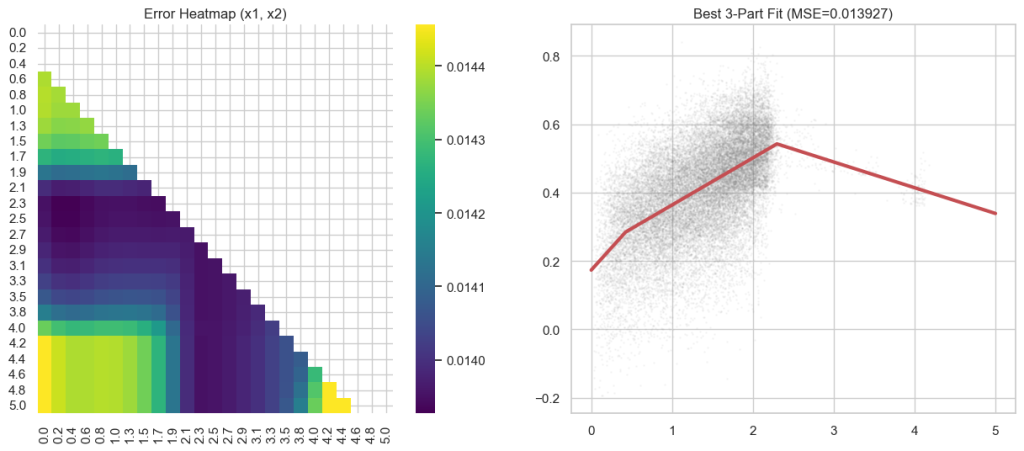
I did some manually tweaking to this to ensure that the normalization function was always increasing. I’ve also updated the score breakdown in the dashboard to reflect the weights. Now you can see the total IDF. If you add up the subscores, and divide by the total IDF, you get the total subscore before normalization by the piecewise-linear function above.
Leave a Reply